최근 NLP를 공부하며, 막연히 남들이 작성한 코드를 통해 분류모델을 만들었습니다.
그러다 보니 모델안의 데이터의 흐름을 알 수 없어, RNN계열, 더 나아가 트랜드포머, 버트등의 모델을 이해하는데 어려움을 느꼈습니다.
그래서 데이터의 흐름을 알아가고자 keras의 Sequential 선언 후 사용하는 Embedding에 대해서 알아보고자 합니다.
Embedding 선언
model = Sequential()
model.add(Embedding(len(word_index) + 1,
300,
input_length=max_len))keras에서는 Sequential() 선언 후 Embedding을 추가합니다.
인수
(len(word_index)) + 1 : 단어 목록의 크기
300 : 임베딩의 차원
input_length=max_len : 인풋 시퀀스 길이
예시
아래 세가지의 문장이 있습니다.
["나는 밥을 먹었다", "나는 학교에 갔다", 오늘 학교에 선생님이 오셨다"]

기계는 text를 이해하지 못하기 때문에 정수 인코딩을 진행합니다. 따라서, 아래와 같이 변환합니다.
[[1, 3, 4], [1, 2, 5], [6, 2, 7, 8]]
정수 인코딩을 살펴보면, 1 = "나는" , 2 = "학교에", 8 ="오셨다"로 변환된 것을 볼 수 있습니다.

다음 모든 문장의 길이를 맞추기 위해 padding을 해줍니다. 위의 문장 중 가장긴 문장은 "오늘 학교에 선생님이 오셧다" 이며 이문장의 길이는 "4"입니다. 따라서, 모든 문장의 길이를 4로 맞춰줍니다.
[[1, 3, 4, 0], [1, 2, 5, 0], [6, 2, 7, 8]]
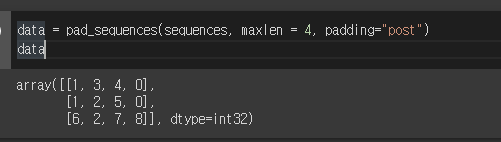
자 이제 Embedding에 들어갈 수 있는 전처리가 완료되었습니다. 앞의 인수를 적용하게되면, 첫 번째 단어 목록의 크기의 경우 1~8단어가 있습니다. 그런데 +1을 해주는 이유는 패딩을 위한 토큰0을 포함하기 위함입니다.
임베딩의 차원은 100으로 정하며, input_length는 앞서 정한 4로 맞춥니다. 그럼 준비한 input data를 Embedding에 넣어 output의 형태를 확인해보겠습니다.
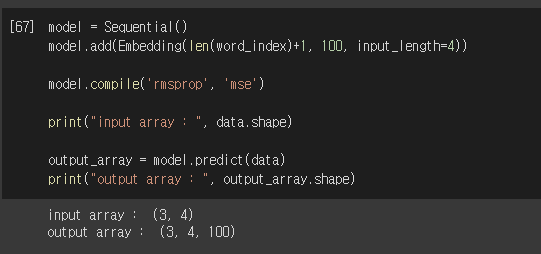
기존의 3, 4의 input data가 3, 4, 100의 output data로 출력되었습니다. 이렇게 된 이유는 각각의 단어들 예를들어 나는이란 단어가 기존의 1로 정수 인코딩 되었다면, Embedding층을 통해 100차원으로 변경된 것 입니다. 이부분을 확인하기 위해 첫번째 문장의 나는과 두번째 문장의 나는을 출력해 보겠습니다.

각 벡터의 값이 같음을 확인할 수 있습니다. 또한 여기서 중요한 점은 이 벡터들은 고정된 값이 아닌 학습을 통해 변화되는 값임을 인지해야합니다.
아래 그림은 위에서 만든 model의 summary 입니다. 왜 학습 Param이 900일까요?
이유는 앞서 정의한 단어의 크기 9 x 백터의 차원 100을 나타내는 것 입니다.

다음은 Embedding을 거친 값이 RNN에서 어떻게 작동하는지 확인하는 글을 포스팅하겠습니다.
'데이터분석 > NLP' 카테고리의 다른 글
| [NLP] Python WordCloud 그리기 (0) | 2021.11.21 |
|---|---|
| [Keras] RNN 내부동작 알아보기 (0) | 2021.08.05 |
| [soynlp] 띄어쓰기 교정 모델 (0) | 2020.05.11 |