# 상위 6개 종목 티커 가져오기
sb = nasdaq.head(6)
sb_li = sb['Symbol']
fig, axes = plt.subplots(2,3, figsize = (15,10))
for n in range(len(sb_li)):
# 주식 별 10년치 종가 가져오기
axes[n//3,n%3].plot(fdr.DataReader(sb_li[n], '2012','2022')['Close'])
axes[n//3,n%3].set_title(sb_li[n])
plt.show()
자 나스닥과 뉴욕증권거래소, 아멕스의 주식 종목들을 가져왔습니다. 모든 주식종목들을 합치기 전에 각각의 거래소들을 확인할 수 있도록 Indexes Column을 생성하였습니다. 그럼 주식데이터들을 하나로 합치겠습니다.
# 데이터 합치기
df = pd.concat([nasdaq, nyse,amax])
# Symbol이 중복되는 데이터 제거
df = df.drop_duplicates('Symbol')
#데이터 shape 확인
print(df.shape)
# 상위 10개 데이터 확인
df.head(10)
총 7882개의 미국주식을 불러왔습니다. 상위 10개를 조회하니 나스닥 시총 상위 10개 종목들이 보입니다.
Visual Studio Code를 사용할 때 마다,내가 선택한 Anaconda의 가상환경에 접속되게 하는 설정 방법입니다. 가상환경을 사용하는 이유는, 프로젝트마다 다양한 라이브러리를 설치하게 되며, 기존의 라이브러리를 업데이트 할 경우, 일어나는 충돌 방지할 수 있습니다. 또한 다른 환경에서 프로그램을 동작 할 경우 일어나는 버전문제를 해결할 수 있습니다.
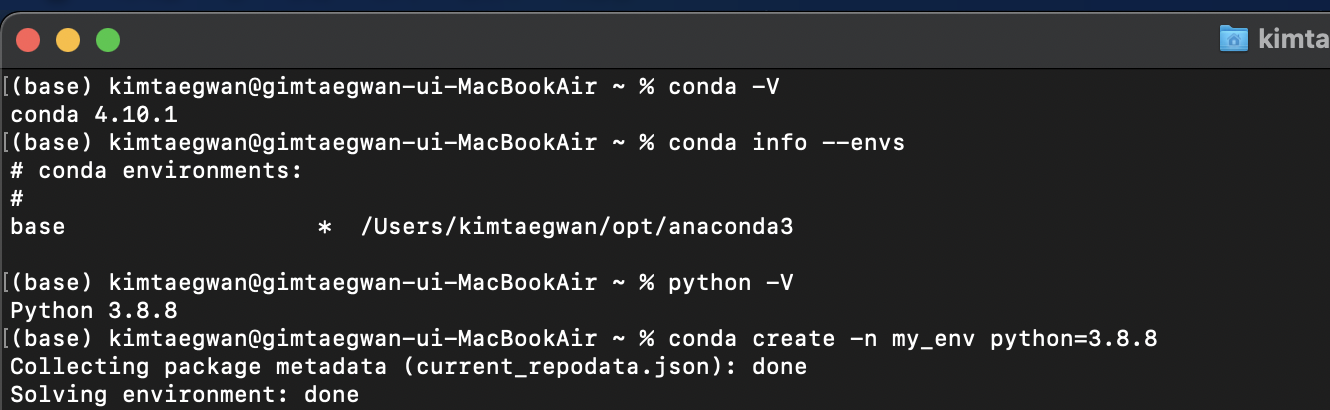
- conda create -n my_env python=3.8.8 : python버전이 3.8.8인 가상환경 my_env생성, 파이썬 버전 지정하지 않을 경우 최신버전 설치 됩니다.
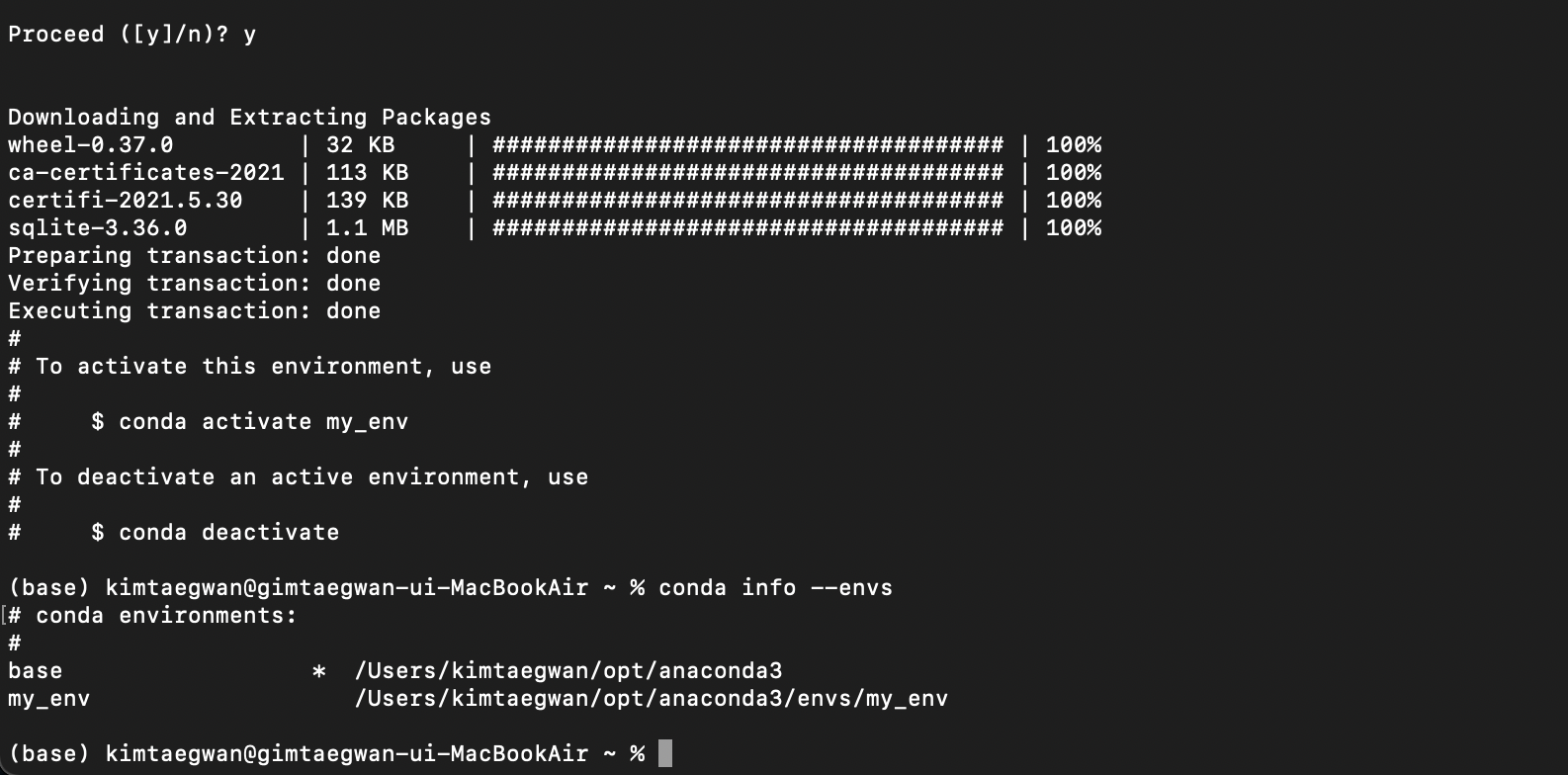
5. 설치된 가상환경 확인
중간에 y/n이 나올 경우 y를 입력하면 됩니다. 설치 후 conda info --envs를 입력하면 my_env 가상환경이 설치된걸 확인할 수 있습니다.
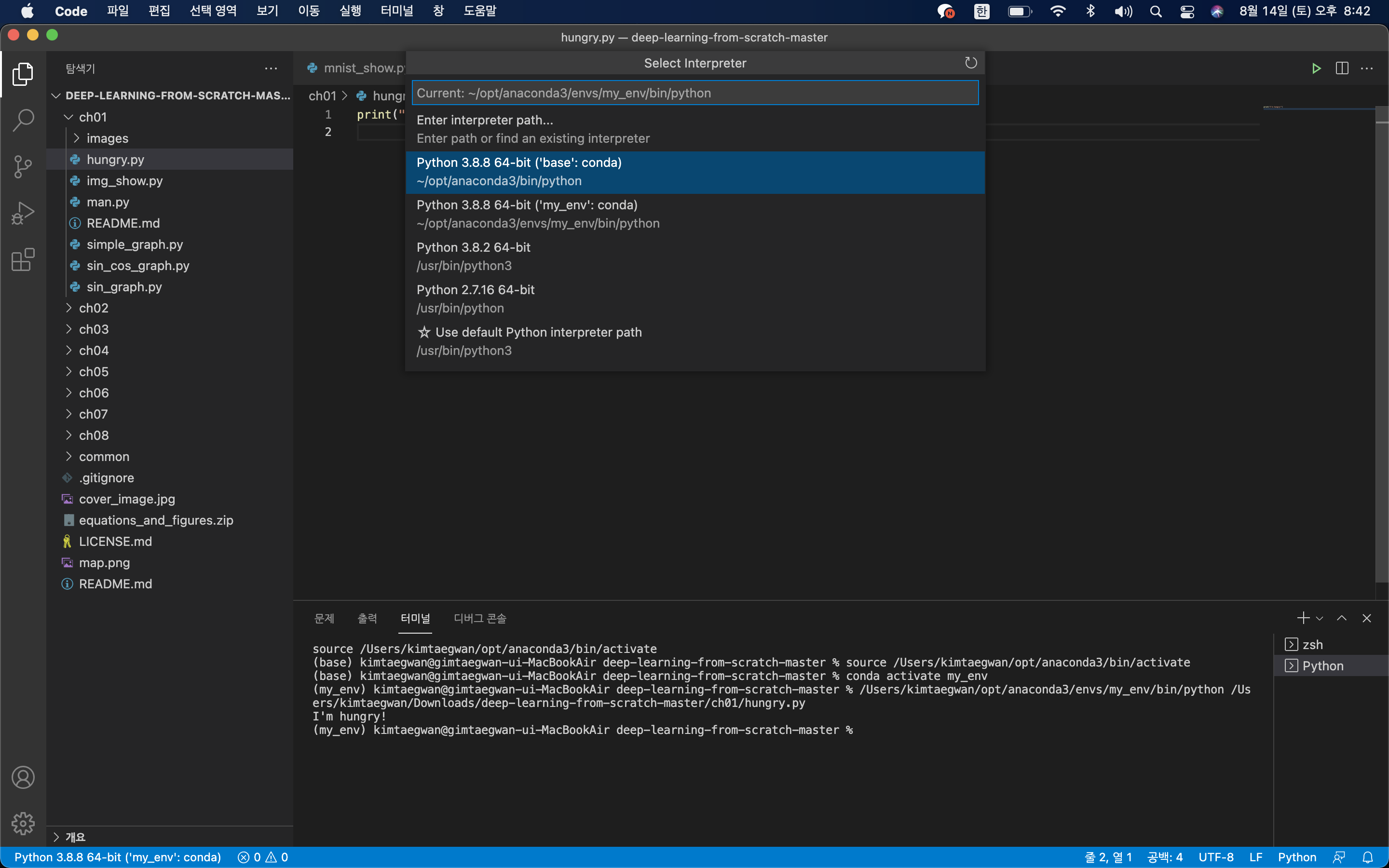
6. VScode 새로 만든 가상환경 설정
command + shift + p 입력 후 Select interpreter 선택하게 되면, 설치한 콘다 환경과, 새로 만든 가상환경이 보입니다. 새로 만든 가상환경 선택 후 hungry.py를 실행해보겠습니다.익숙하신분도 있겠지만, 밑바닥 부터 시작하는 딥러닝1의 코드입니다.
실행하면 vscode에서 자동으로 가상환경을 활성화 시킵니다. conda activate my_env
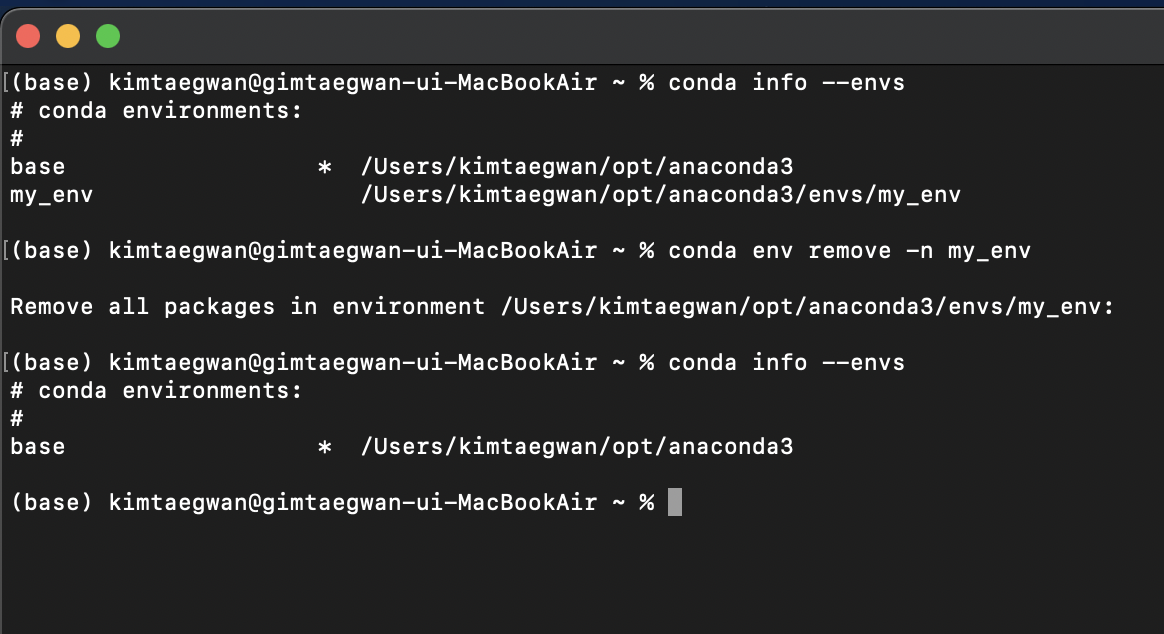
7. 가상환경 제거
새롭게 만든 가상환경이 필요없다는 가정 하에 삭제 하겠습니다. 제거 후 conda info --envs로 확인하면 basd 환경만 남아있는걸 볼 수 있습니다.
RNN을 공부하면서 이해가 가지 않는 부분들이 많았습니다. 은닉층과 출력층은 같은 크기인가? RNN의 아웃풋은 Y값인가? 아니면 은닉값인가?
RNN을 공부하다 보면 아래의 그림들을 많이 볼 수 있습니다. 왼쪽의 그림은 RNN을 통과하여 결과값 까지의 흐름을 나타낸 것이며, 오른쪽 그림은 RNN내부의 구조를 나타낸 것입니다. 따라서 이번 RNN을 공부하는데 있어 결과값은 출력하지 않으며 RNN은 은닉상태를 출력한다고 생각하면 됩니다. 두 그림을 같은 그림으로 혼동하시면 안됩니다.
RNN
RNN의 특징은 입력이 은닉층 노드(A)에서 활성화 함수(tanh)를 지나 나온 결과를 출력으로 보냄과 동시에 은닉층 노드(A)로 다시 보내 다음 들어올 입력을 계산할 때 도움을 줍니다. 그림은 아래와 같습니다.
왼쪽의 그림을 나열하면 오른쪽의 그림과 같이 펼칠 수 있습니다.
예를 들어 "나는 밥을 먹었다" 라는 문장을 RNN의 입력으로 받는다고 생각하면, 우선 "나는"의 입력벡터가 x0의 입력으로 들어가며 은닉측 노드(A)와 활성화함수를 지난 결과값이 h0 출력 벡터로 보내집니다. 그 다음 "밥을"의 입력벡터가 x1의 입력으로 들어가며, x0의 은닉측에서 나온 값은 x1의 은닉층으로 보내지며, 이를 은닉 상태(hidden state)라고 합니다.
RNN
Input
Embedding에서 나온 output이 RNN의 입력으로 들어가게 됩니다.
앞선 예에서 아래 3개의 문장은 전처리 및임베딩을 거쳐 3, 4, 100의 Shape을 가졌습니다.
그렇다면 임베딩을 거쳐 RNN을 통과한 output은 어떤 형태일까요? 기억해야 할 점은 지금 설명하는 부분은 분류, 번역등의 task를 위한 출력층까지의 단계를 설명하는 것이 아니라 RNN 층에 대한 설명이며, RNN층이 리턴하는 결과값은 출력층의 값이 아닌 은닉상태 입니다.
Output 1
"나는 밥을 먹었다"의 문장을 RNN의 입력으로 넣어보겠습니다. 앞서 Keras Embedding층을 거친 값을 가져오겠습니다. 나는 밥을 먹었다는 띄어쓰기 기준으로 3개의 단어지만 앞서 가장 큰 길이인 4로 padding을 했기 때문에 시퀀스 길이가 4이며, 단어 백터의 차원의 경우는 100으로 Embedding를 통과했습니다. 또한, RNN의 입력을 위해 batch size를 추가하였습니다. 하나의 문장이기 때문에 1을 추가했습니다. RNN 층은 (batchsize, sequence_length, input_dim) 크기의 3D 텐서를 입력으로 받습니다.
1, 4 , 100의 입력이 들어가 1, 3의 출력이 나왔습니다. 1, 3은 마지막 시점의 은닉 상태 입니다. 출력 벡터 차원은 hidden_size의 값인 3입니다.
아래 그림은 나는 밥을 먹었다의 문장이 embedding을 거쳐 rnn의 입력, 출력과정을 나타낸 그림입니다.
Output 2
RNN에는 return_sequences라는 옵션이 있습니다. 기본은 Fasle입니다. True일 경우 어떤 output을 출력할까요?
기존 1, 3출력이 아닌 1, 4, 3의 출력을 나타냅니다. 그렇다면 return_sequences=True의 역할은 무엇일까요? 바로 모든 셀의 은닉상태를 retrun한다고 생각하면됩니다.
아래 그림은 나는 밥을 먹었다의 문장이 embedding을 거쳐 rnn(return_sequences=True)의 입력, 출력과정을 나타낸 그림입니다.
그러다 보니 모델안의 데이터의 흐름을 알 수 없어, RNN계열, 더 나아가 트랜드포머, 버트등의 모델을 이해하는데 어려움을 느꼈습니다.
그래서 데이터의 흐름을 알아가고자 keras의 Sequential 선언 후 사용하는 Embedding에 대해서 알아보고자 합니다.
Embedding 선언
model = Sequential()
model.add(Embedding(len(word_index) + 1,
300,
input_length=max_len))
keras에서는 Sequential() 선언 후 Embedding을 추가합니다.
인수
(len(word_index)) + 1 : 단어 목록의 크기
300 : 임베딩의 차원
input_length=max_len : 인풋 시퀀스 길이
예시
아래 세가지의 문장이 있습니다.
["나는 밥을 먹었다", "나는 학교에 갔다", 오늘 학교에 선생님이 오셨다"]
기계는 text를 이해하지 못하기 때문에 정수 인코딩을 진행합니다. 따라서, 아래와 같이 변환합니다.
[[1, 3, 4], [1, 2, 5], [6, 2, 7, 8]]
정수 인코딩을 살펴보면, 1 = "나는" , 2 = "학교에", 8 ="오셨다"로 변환된 것을 볼 수 있습니다.
다음 모든 문장의 길이를 맞추기 위해 padding을 해줍니다. 위의 문장 중 가장긴 문장은 "오늘 학교에 선생님이 오셧다" 이며 이문장의 길이는 "4"입니다. 따라서, 모든 문장의 길이를 4로 맞춰줍니다.
[[1, 3, 4, 0], [1, 2, 5, 0], [6, 2, 7, 8]]
자 이제 Embedding에 들어갈 수 있는 전처리가 완료되었습니다. 앞의 인수를 적용하게되면, 첫 번째 단어 목록의 크기의 경우 1~8단어가 있습니다. 그런데 +1을 해주는 이유는 패딩을 위한 토큰0을 포함하기 위함입니다.
임베딩의 차원은 100으로 정하며, input_length는 앞서 정한 4로 맞춥니다. 그럼 준비한 input data를 Embedding에 넣어 output의 형태를 확인해보겠습니다.
기존의 3, 4의 input data가 3, 4, 100의 output data로 출력되었습니다. 이렇게 된 이유는 각각의 단어들 예를들어 나는이란 단어가 기존의 1로 정수 인코딩 되었다면, Embedding층을 통해 100차원으로 변경된 것 입니다. 이부분을 확인하기 위해 첫번째 문장의 나는과 두번째 문장의 나는을 출력해 보겠습니다.
각 벡터의 값이 같음을 확인할 수 있습니다. 또한 여기서 중요한 점은 이 벡터들은 고정된 값이 아닌 학습을 통해 변화되는 값임을 인지해야합니다.
아래 그림은 위에서 만든 model의 summary 입니다. 왜 학습 Param이 900일까요?
이유는 앞서 정의한 단어의 크기 9 x 백터의 차원 100을 나타내는 것 입니다.
다음은 Embedding을 거친 값이 RNN에서 어떻게 작동하는지 확인하는 글을 포스팅하겠습니다.
import urllib
from random import randint
# a는 pdf주소가 저장된 list / b는 pdf문서 이름이 저장된 list
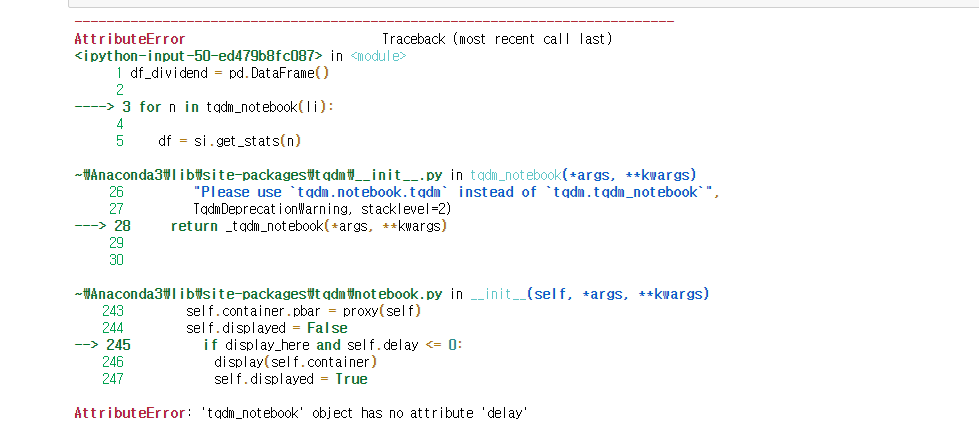
for i, n in enumerate(tqdm_notebook(a)):
#random sleep
sleep(randint(1,10))
#주소를 통해 파일 다운로드
urllib.request.urlretrieve(n, "{}.pdf".format(b[i]))